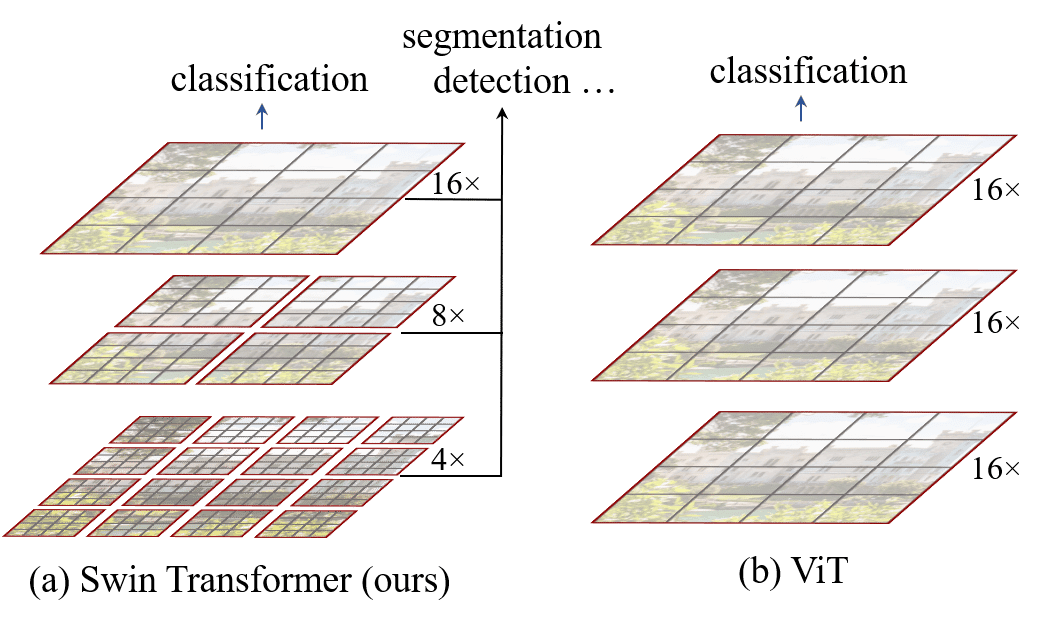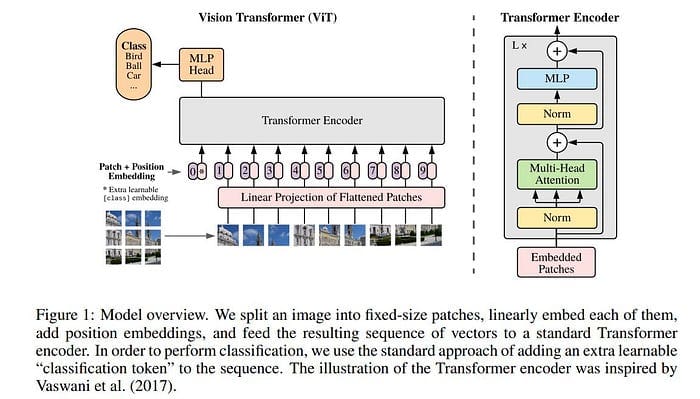
Since transformers operate on a sequence of vectors, we need some way to convert the image into a 1D sequence for the transformer to process. Creating patches also reduces computational complexity and preserves the image’s local spatial structure.
An image is split into a sequence of non-overlapping patches to accomplish this.
If the input image has dimensions ![]() (where
(where ![]() is height,
is height, ![]() is width, and
is width, and ![]() is the number of channels), the image is divided into
is the number of channels), the image is divided into ![]() patches
patches ![]() . Each patch is flattened into a vector of size
. Each patch is flattened into a vector of size ![]() where the patch size
where the patch size ![]() is set
is set ![]() . From this point on, each patch is treated as a “token,” akin to words in Natural Language Processing (NLP) tasks.
. From this point on, each patch is treated as a “token,” akin to words in Natural Language Processing (NLP) tasks.
In the figure below, we have ![]() patches, with each patch of size
patches, with each patch of size ![]() and the output of this step is as follows:
and the output of this step is as follows:
![]()

A linear projection layer is a crucial step in reformatting and transforming each patch into a suitable vector representation. This layer may be useful for dimensionality reduction, ensuring the dimensions align with what the transformer model input expects and mapping to a latent space to learn better data representations.
Each flattened patch is passed through a learnable linear projection. If a patch has dimensions ![]() , it is linearly projected into a fixed dimension
, it is linearly projected into a fixed dimension ![]() , creating patch embeddings of size
, creating patch embeddings of size ![]() . Mathematically, the projection can be represented as:
. Mathematically, the projection can be represented as:
![]()
Where ![]() the
the ![]() flattened patch
flattened patch ![]() is the projection matrix, and
is the projection matrix, and ![]() the resulting patch embedding is.
the resulting patch embedding is.
For example, let’s say we wanted to reduce the dimensionality of the flattened patch to reduce the computational complexity.
We can do this by setting ![]() , resulting in the following linear projection:
, resulting in the following linear projection:
![]()
![]()
Where ![]() is the positional embedding for the
is the positional embedding for the ![]() patch, and
patch, and ![]() is the embedding. This produces a final sequence representation
is the embedding. This produces a final sequence representation ![]() passed to the transformer blocks.
passed to the transformer blocks.
![]()
Where ![]() ,
, ![]() , and
, and ![]() are the queries, keys, and values derived from the patch embeddings? This attention mechanism captures the relations between different patches globally, followed by pointwise feed-forward layers (MLPs) to refine the representations.
are the queries, keys, and values derived from the patch embeddings? This attention mechanism captures the relations between different patches globally, followed by pointwise feed-forward layers (MLPs) to refine the representations.