

A data mesh is a decentralized approach to data architecture that’s been gaining traction as a solution to the challenges posed by large and complex data ecosystems. It’s all about breaking down data silos, empowering domain teams to take ownership of their data, and fostering a culture of data collaboration. And when it comes to implementing a data mesh, one platform has been making waves in the data world: the Snowflake Data Cloud.
In this blog, we will explore what a data mesh architecture is, why Snowflake is the right data warehousing platform to build your data mesh in, and all the prominent ways you can create a data mesh using Snowflake’s various features.
What is a Data Mesh Architecture?
A data mesh is a conceptual architectural approach for managing data in large organizations. Traditional data management approaches often involve centralizing data in a data warehouse or data lake, leading to challenges like data silos, data ownership issues, and data access and processing bottlenecks.
Data mesh proposes a decentralized and domain-oriented model for data management to address these challenges.

What are the Advantages and Disadvantages of Data Mesh?
Advantages of Data Mesh
Improved data quality due to domain teams having responsibility for their own data.
Reduced data silos by promoting data sharing and reusability.
Faster data delivery through a self-structured data infrastructure and no central data team to cause a bottleneck
Disadvantages of Data Mesh
Implementing a data mesh can be complex and may require a significant cultural shift within the organization.
Transitioning to a data mesh architecture may require an initial investment in technology, training, and organizational restructuring.
Ensuring domain teams have access to the right tools and infrastructure to manage their data can be a logistical challenge, and organizations must invest in appropriate resources.
Why use Snowflake for Data Mesh?
Snowflake is being used successfully as a data platform by many companies that follow a data mesh approach. There is no single technology platform that provides a complete end-to-end solution to support the data mesh concept. However, Snowflake offers many of the capabilities needed for a self-service data platform, enabling a distributed, domain-driven architecture and offering capabilities to help implement data as a product and federated computational governance.
Use Cases for Data Mesh in Snowflake
Data mesh has become a very popular topic in the data engineering world as of late, but it’s not for everyone. Here are some common scenarios that you may find your company in where data mesh would be beneficial:
Complex Data Ecosystem: When your organization has a diverse range of data sources, types, and formats, making centralized management and processing impractical or inefficient.
Data Quality and Governance: To improve data quality and governance by allowing domain-specific teams to take ownership of their data, ensuring its accuracy, compliance, and security.
Data Monetization: When you want to generate revenue from your data assets by structuring and packaging data for sale to external customers or creating data-driven products and services.
- Cultural Transformation: When you aim to foster a cultural shift towards data ownership and accountability within your organization, encouraging data-driven decision-making at all levels.
Prerequisites for Building a Data Mesh: Organizational Transformation Required
First and foremost, data mesh is an organizational transformation. This transformation has many non-technical implications but often requires changes at the IT architecture and technology level.
Data mesh represents a significant shift in how organizations manage and leverage their data assets. It is not just a technological change but a comprehensive rethinking of the entire data ecosystem and how data is treated as a strategic asset within an organization.
Therefore, it’s best to plan the organizational shift before creating the data mesh begins. Here are the steps needed before any technological change can begin:
Leadership Buy-In
Start by securing buy-in from executive leadership. Leaders should understand the benefits of data mesh and be committed to driving the change.
Educate the Organization
Conduct workshops, training sessions, and informational meetings to educate employees about the principles and benefits of data mesh. Ensure that everyone understands why the change is necessary.
Cross-Functional Teams
Organize cross-functional teams or data domains responsible for their own data products. These teams should include representatives from data engineering, data science, data governance, and business units.
Ownership and Accountability
Clearly define ownership and accountability for each data domain. Ensure that teams understand their responsibilities for data quality, reliability, and accessibility.
Skill Development
Invest in skill development. Provide training and resources to help teams acquire the necessary skills for data mesh, such as data product management, data engineering, and data governance.
Communication Strategy
Develop a comprehensive communication strategy. Regularly communicate the progress, successes, and challenges of data mesh implementation. Address concerns and provide forums for feedback.
Documentation and Best Practices
Document best practices, lessons learned, and success stories. Create a knowledge repository to facilitate knowledge sharing within the organization.
How to Use Snowflake’s Features to Build a Data Mesh
Now that your organization is prepared to make the change to data mesh, the technical challenge begins with how to separate the newly formed data domains. Luckily, Snowflake has topology options to support distributed domains.
Database Per Domain
A popular approach is to utilize a single Snowflake account. In this setup, various domains operate within distinct databases and autonomous compute clusters, each serving as its independent environment. These domains have the flexibility to allocate one or more databases and clusters to cater to their development, testing, and production requirements.
The platform’s self-service nature empowers domains to leverage Snowflake’s ZeroCopy Cloning capabilities, allowing them to effortlessly and frequently create or recreate development and testing environments. Furthermore, within each domain, different users can autonomously initiate and scale their compute clusters to suit their specific needs.
While this self-service approach provides agility, it’s worth noting that controls such as cost and consumption monitoring and quotas can be established at the domain level or other granular levels within the user and resource hierarchy.
The advantages of having all the domains in one Snowflake account are:
Access to data products can easily be done by setting intra-database permissions.
Centralized network, security, and governance policy administration simplifies the overall management.
Disaster recovery is simpler as it only requires one other account in another region or cloud to support.

Account Per Domain
An alternative configuration permits each domain to function within its individual Snowflake account. These accounts may exist within the same cloud region or across diverse cloud platforms. The overarching Snowflake Data Cloud infrastructure facilitates seamless data sharing among companies and domains across various accounts, regions, and cloud platforms, offering standardized access to each other’s data products in a secure and well-governed manner. Some organizations are leveraging this capability to establish a multi-region, multi-cloud data mesh.
The resulting topology is logically very similar to using a separate database per domain,
except that each domain now “owns” a separate Snowflake account and uses the Snowflake data sharing and marketplace capabilities to make data products accessible to others.
The advantages compared to the database per domain approach can be the following:
Data sharing and collaboration capabilities can be used across domains.
Global naming standards can be applied more easily as each account is an independent namespace.
Cloud platforms and regional preferences can be supported.
There is separate security and user management per account.
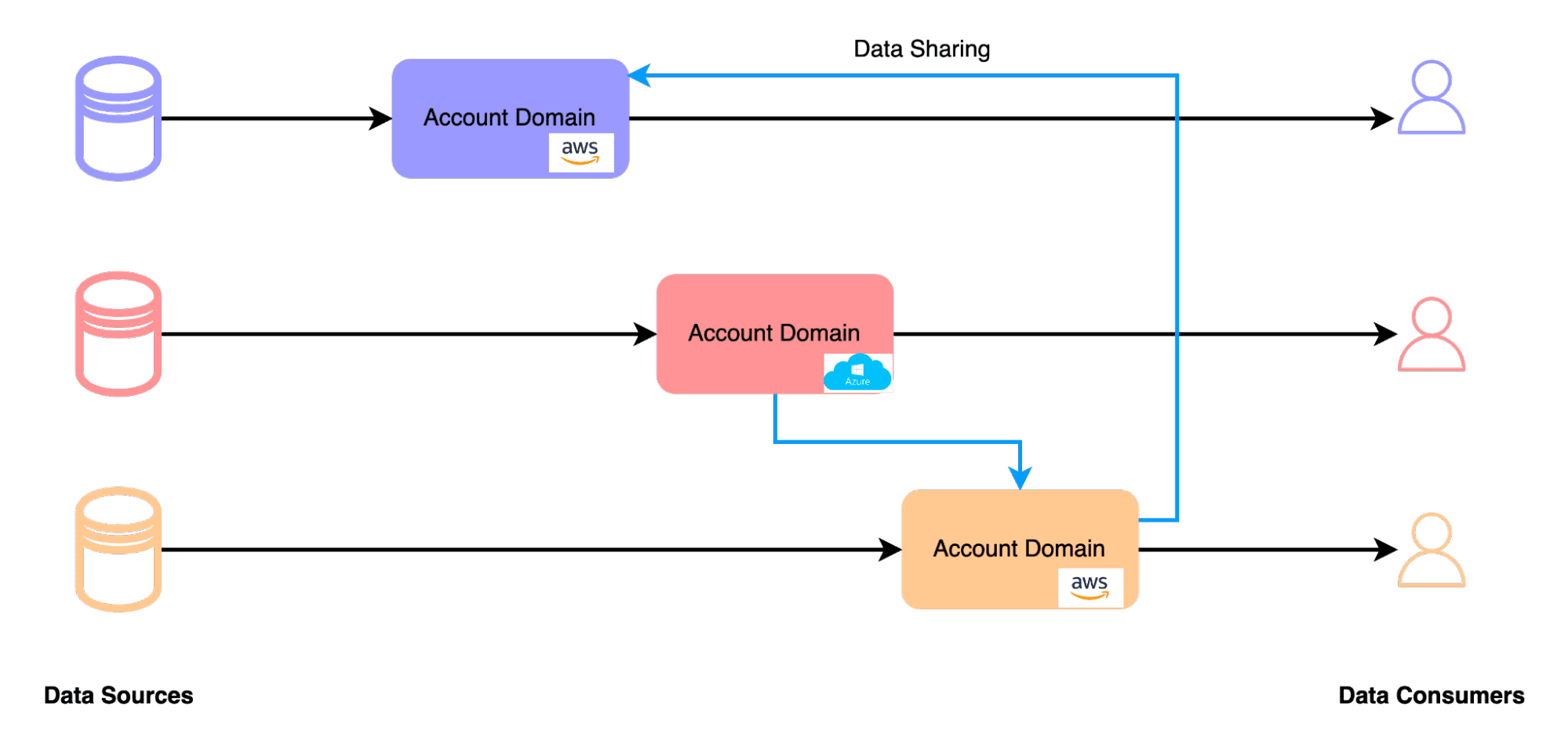
Heterogeneous Domains
Another possibility is to integrate non-Snowflake environments into the topologies already mentioned in this blog. Such integrations lead to a diverse architecture in which not all domains employ a uniform, domain-agnostic data platform for executing their pipelines and developing data products. Frequently, this choice is driven by the need to capitalize on various repositories or technology stacks already in place across different segments of the organization.
Going this route will almost certainly drive up the cost and complexity of your company’s data mesh. The greater the heterogeneity of the systems used makes it much more difficult to keep the organization in line with differing skills needed per system, performance differences, and security concerns.
An intermediate layer would be required in the data mesh in which Snowflake can act as a “proxy” that serves the data products with consistent governance, security, interoperability, etc., to the rest of the data mesh.
This intermediate layer could be Kafka topics that feed into Snowflake via continuous ingestion followed by automatic updates of data products in Snowflake. Or any of the various cloud storage buckets could be used (Amazon S3, Azure Blob Storage, etc.) where Snowflake can either auto-ingest new files from storage buckets continuously for best performance, security, and automatic management or expose read access to such files as External Tables to the rest of the data mesh.
Since Snowflake External Tables are first-class data objects, they can be secured and governed, joined, and even shared via Snowflake collaboration, much like other data objects in Snowflake. This enables Snowflake to act as an integration layer that can expose outside data in a consistent and governed manner without necessarily ingesting and duplicating the data.

Other Tips for Building Your Data Mesh
Be pragmatic. Don’t aim at implementing the “perfect” data mesh, but to be guided by addressing their specific pain points and objectives. Companies should focus on their actual requirements to maximize impact.
Start small, expand incrementally, and work your way up along the data mesh maturity curve over time. For example, start with one or two domains and data products to satisfy an immediate business need and then exploit the early success to expand the mesh.
Be mindful of cost and complexity. For example, keeping the set of tools on the self-service data platform as small and as consistent as possible across all domains while satisfying all critical domain requirements has proven beneficial.
Define incentives and success criteria early on, including measurable KPIs for domains, data products, the self-service data platform, and governance controls.
Closing
The concept of a data mesh is a transformative paradigm in the ever-evolving landscape of data architecture. It represents a shift towards decentralization, breaking down traditional data silos and empowering domain teams to unlock the full potential of their data.
From enhanced collaboration to improved data ownership, Snowflake provides a robust foundation for building a data mesh that adapts to the dynamic demands of modern data ecosystems. We hope this exploration has shed light on the potential of data mesh and how Snowflake can help on this transformative journey.
Whether you’re just beginning to embark on this path or seeking to optimize your existing data mesh, phData can help! As the 2022 & 2023 Snowflake Partner of the Year, phData has the expertise and experience to help your organization make data mesh a success story for your data journey.
Interested in a Free Data Mesh Consultation?
Our experts would be happy to help! In a casual Zoom call, someone from our data engineering team will reach out to you (and anyone else from your team interested) and schedule a 30-60-minute meeting to answer any questions you have around building a data mesh architecture, succeeding with the modern data stack, and more!
Note: This link will take you to our general contact form. If you’d be so kind as to fill it out and copy and paste this response in the message section – “I’m here for the free data mesh consultation” –
it would be much appreciated!
FAQs
Data Mesh is a decentralized, domain-oriented approach that focuses on data ownership and autonomy within specialized teams, promoting collaboration and accountability. Whereas Data Fabric is a more centralized approach that creates a unified data layer, allowing for easier data access and integration across the organization, with a focus on data harmonization and governance.
A data mesh is a concept that has been primarily developed to address the challenges faced by large and complex organizations dealing with massive and diverse data ecosystems. However, whether a data mesh is suitable for organizations of all sizes depends on several factors, including data complexity, resource availability, and scalability plans, among other things.









