

Anyone who has interacted with ChatGPT has most likely performed prompt engineering, tweaking the question (prompt) sent to the model to return a quirky, funny, or more accurate response. In the context of developing a generative AI application, prompt engineering involves not only tweaking the prompt but also establishing a framework that enables users to rapidly and iteratively develop prompts.
This blog provides an overview of how to approach prompt engineering from a workflow and architecture perspective when developing a generative AI application.
Why Prompt Engineering is Necessary for a Gen AI Application
A production-ready generative AI application is a modular system that has been fine-tuned to produce the most accurate response. To arrive at this state, developers had to undergo a tedious process of evaluating embedding models and data retrieval methods to return the most relevant contextual data.
Additionally, they had the added challenge of selecting a large language model that best fits the application’s use case. Tuning prompts were also used to elicit the most accurate response from this system of modular technologies.
Imagine a scenario where the development team wants to swap out the existing LLM in the application for a different or newer version of the same model. It is naive to think that swapping the LLM would maintain or achieve better application performance, as each LLM has its own unique behaviors.
Additionally, changes in user behavior over time can introduce new data to the LLM, affecting application performance since the prompt was initially tuned to a known set of test cases. For these reasons, continuous prompt engineering is necessary during the initial development process and the evolution of the application in production to account for different LLMs or changes in user behavior, also known as data drift.
Approaches to Prompt Engineering
In Data Science 101, students are often taught that data science is both an art and a science. This statement also holds true for prompt engineering. It is easy to achieve good results with a simple prompt template:
prompt_template = """
Given the following information, answer the question.
Context:
{% for document in documents %}
{{ document.content }}
{% endfor %}
Question: {{ question }}
Answer:
"""
The size of the LLM can influence how prompting can be approached. For smaller, open-source models, examining the training data to see the types and formats of prompts used during training can provide valuable insight into how to format prompts to elicit desired outputs. On the other hand, larger, closed-source models are often trained with a large quantity and variety of data, enabling them to produce acceptable outputs even with poor prompt structure.
Regardless of model size, consistently achieving great results requires an iterative process of crafting a prompt that can effectively handle all known edge cases and the variety of data the application may be exposed to. As the generative AI space has evolved, researchers and practitioners have proposed different methods of iteratively developing prompts.
A consensus emerging from the industry is to designate the prompt engineering role to the subject matter experts. Similar to how neurologists would be the best candidates to label a brain tumor detection dataset, subject matter experts, not always the application developers, would be the best candidates to craft prompts. Take, for example, a fast food chain developing a generative AI application to help operators debug equipment issues at the restaurant. A developer may not know all the details and processes of restaurant operations, but a seasoned customer service or product manager would.
PromptLayer is an example of a product offering that allows the prompt engineer to visually craft, test, and publish prompts in a workflow decoupled from the agent development workflow.

An emerging alternative approach to prompt engineering is programmatic prompting. A generative AI application’s logic can have multiple layers of prompts. Manually tuning prompts at each layer in isolation and then in conjunction is tedious and must be repeated whenever the agent logic, data, or LLM is altered.
DSPy, a Python framework developed by Stanford, emphasizes programming over prompting by abstracting prompts turning away from humans. At a high level, DSPy’s framework accomplishes this by algorithmically optimizing a prompt toward maximizing a given metric by comparing prompt output results to an evaluation dataset.
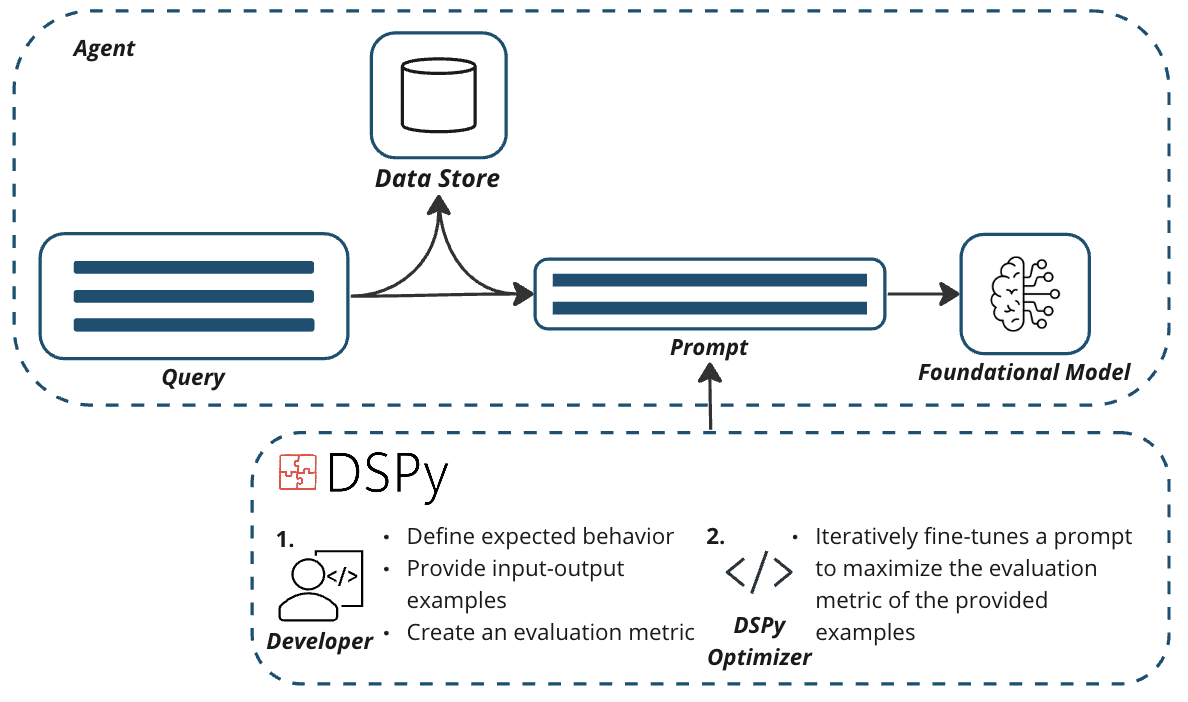
Validating Prompts
Whether prompts are tuned manually or programmatically, prompt engineering is still an iterative process that contains a validation step to evaluate prompt performance. Unlike traditional machine learning domains, such as time series forecasting, where model outputs can be evaluated against a ground truth dataset, evaluating prompts is more complex.
The fundamental issue with validating prompt performance is that LLMs themselves are not idempotent. While it is possible to create a ground truth dataset containing the expected outputs for a set of user questions and relevant documents to see how a prompt performs, depending on the LLM parameters, the exact same prompt may produce a slightly different response each time.
Given the unstructured nature of generative AI, validation frameworks and products have begun leaning towards using other LLMs to evaluate prompt performance. In fact, both PromptLayer and DSPy offer the ability to use LLMs as the evaluator.
Validating prompts and generative AI applications as a whole is a complex subject that deserves more discussion than a subsection in a blog. This topic is covered more in-depth in the next blog in this series: Testing and Validation.
Conclusion
In early 2023, there was a lot of hype about the prompt engineer as an emerging new role in the tech industry. This role would act as the LLM whisperer, bending LLM behavior to their will. A year has passed, and the prompt engineer role is now dead.
The responsibilities of prompt tuning have been transferred over to subject matter experts or in DSPy’s case, LLM-backed optimization algorithms.
Regardless of the entity responsible for prompt tuning, it is important to have a solid LLMOps foundation in place for a generative AI application in production. An LLMOps foundation, which includes an iterative prompt tuning process, will enable teams to rapidly adapt to modular changes in the application while ensuring performance remains consistent.
To wrap up the series, check out Part 4, which covers Testing and Monitoring.
Want more in-depth examples of prompt engineering?
Check out this blog!











