

We have some uncomfortable truth for you: even if your machine learning (ML) models aren’t wrong now, drift will inevitably affect any model and cause it to lose accuracy over time.
This post discusses some of the most common cues for retraining an ML model.
We’ll discuss why you need to retrain machine learning models, what causes the need for this retraining, and how to recognize the cues that indicate that it is time for retraining. We’ll also touch on the operational and engineering prerequisites to successfully retrain and debug models.
“All models are wrong but some are useful.”
~ George Box
What are the Causes for Retraining ML Models?
The knowledge embedded in a machine learning model is a frozen snapshot of a real-world process imperfectly captured in data.
The required change may be complex, but the reasoning is simple.
As the real world and the engineering around that snapshot change, your model needs to keep up with reality in order to meet the performance metrics achieved in development.
Some retraining schedules present themselves naturally during model development — when the model depends on a data source that is updated periodically, for example. Many changes in data, engineering, or business can be difficult or impossible to predict and communicate. Changes anywhere in the model dependency pipeline can degrade model performance; it’s an inconvenience, but not unsolvable.

Consider a user interacting with a website application. The application may capture clicks to represent this interaction, and these clicks may be monetized under specific business rules.
This data can be used to build a model to predict the lifetime value of that customer or the risk of losing that customer’s business (churn).
Another real-world scenario could be someone purchasing a vehicle. This process gets captured as a purchase order, which gets modeled and stored in a database. Business definitions are then used to calculate profit.
From this, we can build a model to predict profit per car or the length of time required to make a sale.
There is no shortage of ways that these models might fail over time.
- Externally, user profiles or macroeconomic trends may change, degrading our model.
- If the stock market crashes, people will no longer behave in the same way that they were behaving at the time that the model was trained.
- When the COVID pandemic occurred, eCommerce and physical retail behaviors changed drastically.
- Internally, business rules may change: new email subscribers might now be recorded as “warm lead” instead of “new member” within the internal data.
- An advertising campaign may increase demand, a new data source may be added to data capture, or a data source may disappear – the hazards are endless.
A change in any step in the model dependency pipeline may violate the statistical, technical, or business assumptions that were relied upon when the model was built, which will require the model to be retrained.
Cues for Retraining
While we may not have visibility into the entire dependency tree, changes in the pipeline that violate the assumptions of our model will have a measurable impact on the inputs and outputs of our model.
As part of a larger model monitoring strategy, we can monitor the input and outputs of our model and trigger model retraining upon the following events:
- The model’s performance metrics have deteriorated.
- The distribution of predictions has changed from those observed during training.
- The training data and the live data have begun to diverge and the training data is no longer a good representation of the real world.
The common thread running through all these events is monitoring.
Ideally, predictions and the inputs that produced them are logged and easily accessible to facilitate monitoring. The best approach is to tie the model calls to a unique ID which can be used to retrieve the prediction and logging data.
If possible, this prediction should either immediately or eventually be tied to a ground truth label. For example, in a propensity-to-buy model, you would want to update the model using information about whether a purchase actually occurred or not. These ground truths are then used to calculate and visualize a performance metric that should be made available to users across the organization.
Error Rate Based Drift Detection
Detecting drift based on model performance, or “error rate based drift detection,” ties directly to what we care most about — model performance — and is generally simple to implement. In this strategy, when we observe a significant dip in model performance, we retrain our model. The threshold for retraining should be determined based on the performance expectations set during model development.
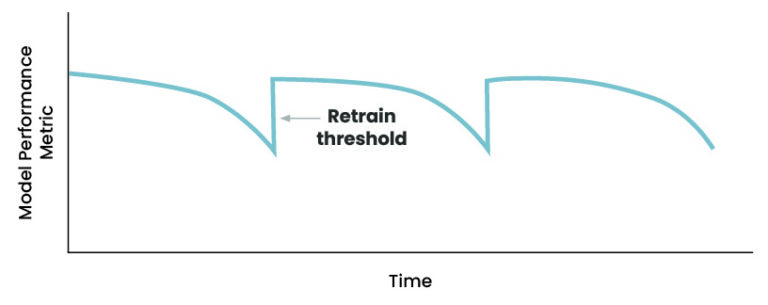
This method presupposes that ground truth labels are eventually available so that the performance metric can be calculated.
If a manual labeling process was part of model development and training, a similar labeling process should also be included in a retraining step. While some model types may not have explicit labels (unsupervised, self-supervised), they should have some measurable business impact that we can monitor.
For example, we may monitor the time a paralegal spent summarizing a deposition after deploying a text summarization model. Monitoring these business metrics enables online experiments (A/B testing, for example) to assess the performance of a machine learning model and trigger retraining if necessary.
Sometimes it’s just not possible to close the loop and find out if our model’s predictions were actually correct; in those instances, we need to rely on other drift detection methods.
Drift Detection on the Target Variable
Even without available labels, we can still monitor the distribution of predictions and compare it to the distribution of predictions that we observed over the training data.
Prediction data for many use cases tend to be univariate or low dimensional, making some of the common methods for comparing distributions easier to implement and interpret.

Some of the more common statistical tests used to compare distributions are the Z-test, Chi-squared, Kolmogorov–Smirnov, Jensen-Shannon, and Earth Mover’s Distance. No matter the chosen metric (similar to error rate-based drift detection) you’ll need to determine a threshold for when retraining becomes necessary.
Drift Detection on the Input Data
Given structured tabular data, we can extend the idea of detecting drift on the target variable to our input variables. In this case, we could generate baseline statistics from our training data for each feature and compare these statistics to those seen in the live data.
This strategy benefits from the possibility of using pre-existing data quality steps or metrics that may already be embedded or available in the data engineering pipeline. Some cloud providers also already have built-in offerings for this approach making it easier to implement than more advanced techniques.
Generating and comparing statistics between data sets should start to tickle our machine learning itch. Alternatively (or additionally), we can train a binary classifier to distinguish between training data and live data. Being able to distinguish between the training data and live data (a better-than-random AUC) suggests that the data has drifted.
Drift Detection is Just the Beginning
Retraining isn’t the end of fixing data drift. It’s a prompt to understand more deeply the internal and external model dependencies.
Debugging model degradation and error analysis can lead to insights about the real world, technical processes, and business processes reflected in the data. In order to facilitate error analysis, debugging, and retraining, machine learning operations, engineering teams need to lay proper groundwork around logging, monitoring, and automation in concert with data engineering teams.
Retraining is part of a larger scope of the model care and maintenance that doesn’t stop when you deploy your model to production. Much of this care and upkeep can and should be automated by a solid MLOps Architecture supported by a quality ML Engineering team.
As the real world and the business processes change, a strategy that doesn’t allocate time for data scientists to update models with analysis based on the latest data and debug models to identify potential problems is bound to fail. Even worse: your model might not fail in such a way that it stops functioning, but it may start to provide predictions and insight that are incorrect in ways that actively harm your business.
So What Should You Do?
- Trace and understand the dependencies of your model.
- Select a drift detection method that’s appropriate for your model and data:
- Error rate
- Target variable
- Input data
- Select a metric and threshold for retraining.
- When the threshold has been crossed:
- Perform error analysis and debug model dependencies for insights
- Retrain your model
- Iterate and improve.
Most cloud providers have services that help with many of the steps above, from setting up model performance monitoring and data quality to integrating notifications.
We prefer the simplest metrics and tests that meet the needs of the business. Complicated methods with negligible impact do nothing but generate technical debt and potentially skeptical end-users.
Takeaways
In this blog, we’ve given a brief overview of
- Why model retraining is necessary
- Where and how drift can occur in the pipeline of model dependencies
- Where to measure drift within your model pipelines, and
- Preliminary options for how to measure drift.
We’ve also established the need for automation and observability around the model dependency pipeline to enable retraining.
In a phrase, model retraining illustrates the prerequisite data engineering, MLOps, and machine learning engineering necessary to deploy a “production-ready” machine learning model.










