

Best practices are a pivotal part of any software development, and data engineering is no exception. This ensures the data pipelines we create are robust, durable, and secure, providing the desired data to the organization effectively and consistently.
However, each software has Unique Selling Points (USPs), so we must tune the best practices according to the tool’s architecture and workings.
In this blog, we will cover the best practices for developing jobs in Matillion, an ETL/ELT tool built specifically for cloud database platforms. The blog will be divided into three broad sections: Design, SDLC, and Security, each with its best practices.
What Are Matillion Jobs and Why Do They Matter?
Matillion is a SaaS-based data integration platform that can be hosted in AWS, Azure, or GCP. It offers a cloud-agnostic data productivity hub called Matillion Data Productivity Cloud. It can connect to multiple data warehouses, including the Snowflake AI Data Cloud, Delta Lake on Databricks, Amazon Redshift, Google BigQuery, and Azure Synapse Analytics.
Matillion Jobs are an important part of the modern data stack because we can create lightweight, low-code ETL/ELT processes using a GUI, reverse ETL (loading data back into application databases), LLM usage features, and store and transform data in multiple cloud data warehouses.
Best Practices for Developing Matillion Jobs
We will group the best practices into three sections, each signifying a software development category. Below are the best practices.
Design Practices
Project and Folder Organization
The hierarchy of organizing jobs in Matillion is as follows:
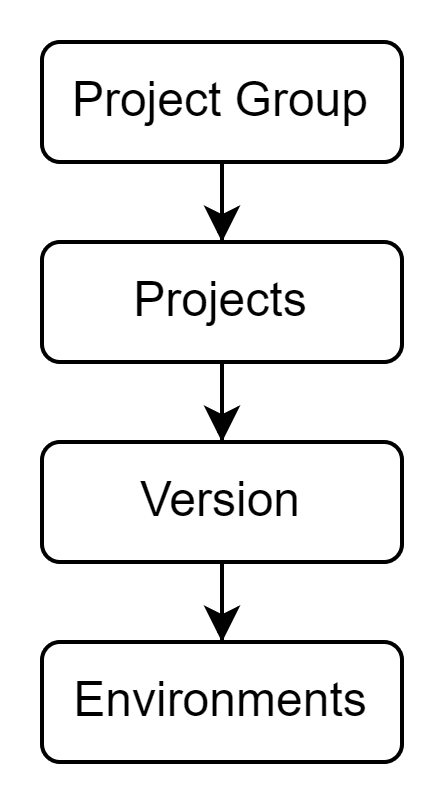
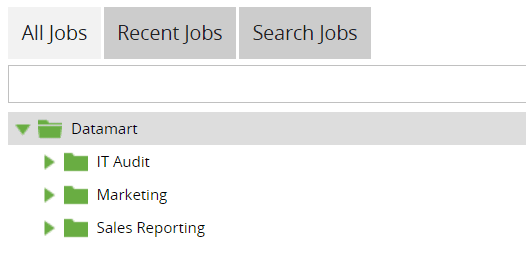
Project Group can represent a tenant in a multi-tenant architecture or the data warehouse layer. Then, there should be separate projects for the business unit to distinguish different business processes clearly. This helps add accountability and ownership of jobs. Below is a sample scenario for 3 business units within an organization for the data mart layer of the data warehouse.
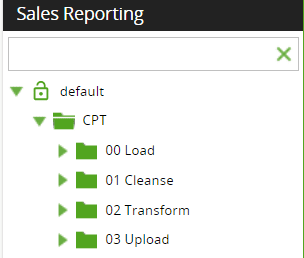
Inside each project, we should create multiple folders for each application/source-target combination, matching the overall data flow of the processes involved. Let’s say you have a downstream application called ‘CPT’ where we are feeding data via Matillion, and it has four high-level steps, namely – Load, Cleanse, Transform, and Upload in sequence; below could be the ideal folder structure –
When creating a pipeline with multiple jobs, i.e., a parent and multiple child job lineage, we should follow a similar naming convention for the child jobs as per the execution sequence. Below is a sample scenario –
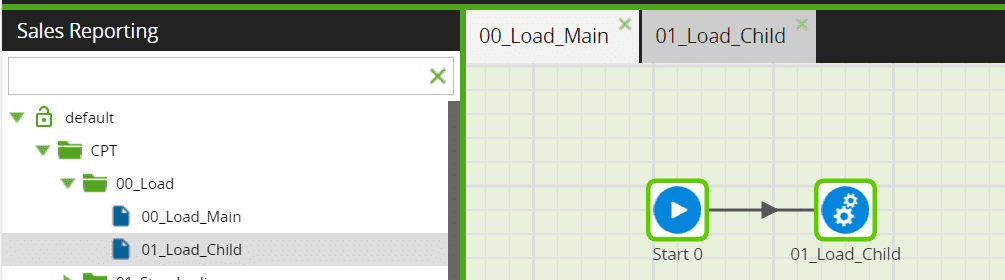
As you can see, the main job has been prefixed ‘00’, and the first child job in the sequence has been prefixed ‘01’. We can continue adding the prefix to the subsequent child jobs, if any.
Environment vs. Job Variables
Matillion offers different types of variables to parameterize a job and make it dynamic. We should follow the following when assigning environment variables and job variables-
Environment Variables should only be used to store values that vary according to the deployment environment (Development, Testing, and Production) or the values that will be used for all jobs across the project—E.g., Database names, Cloud Region, etc. We should not use these variables to store job-specific values. To achieve the same functionality, we should use “project variable” in DPC.
As the name suggests, job variables are for use within the particular job and should not be used to store values that vary according to the deployment environment (Development, Testing, and Production). In DPC, we should use a “pipeline variable” to achieve the same functionality.
Use of Python Component
The Python component, including using Jython to connect to various databases, should not be used for resource-intensive data processing. We should use the Snowflake “SQL Script” component to run the process natively in Snowflake for any resource-intensive data processing. Suppose any external database is required and the specific database component is unavailable. In that case, we can create a stored procedure in that database and call it from the Python component.
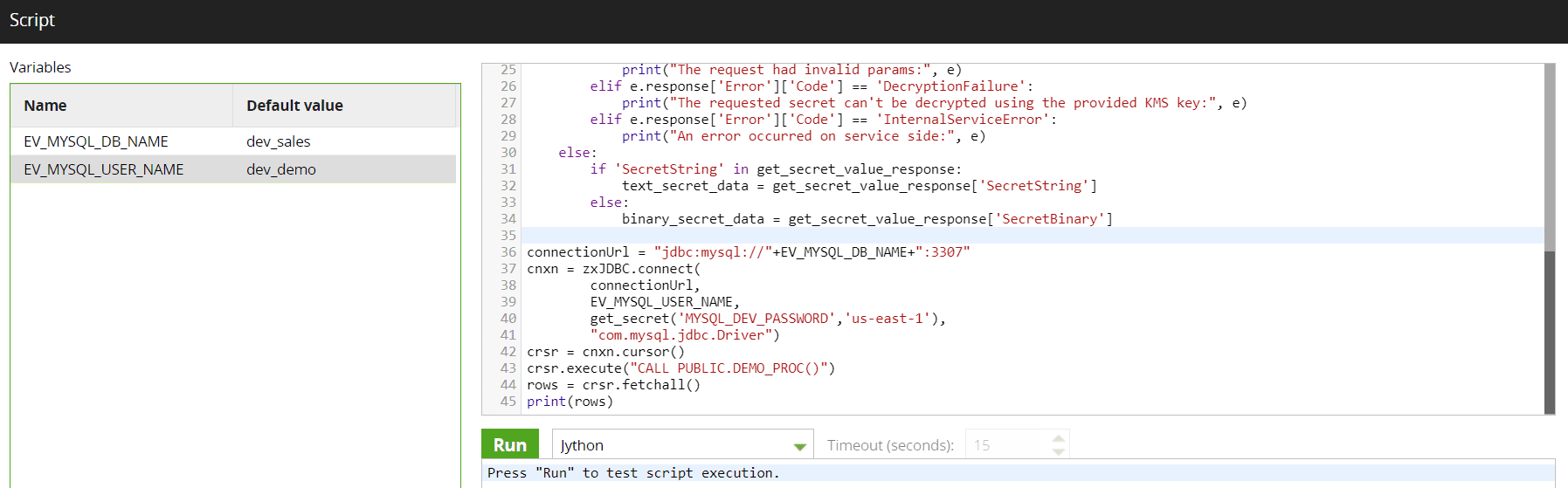
The general use of the Python component should be limited to all kinds of variable manipulation and using small-scale cloud APIs like boto3 for AWS to connect to various cloud services, which cannot be done via the Matillon components.
Error Handling
Idempotency
Wrap the SQL Scripts in a Transaction Using Begin, Commit, and Rollback Components for orchestration jobs so that it is immune to script execution failures.
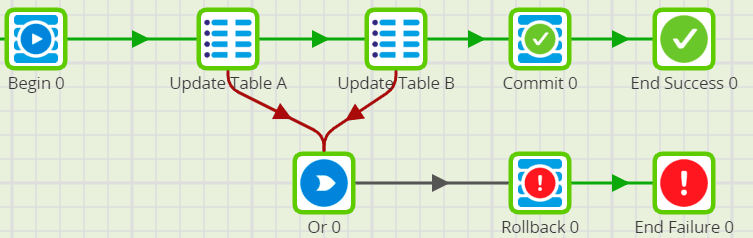
Always have one or more Audit timestamp column(s) in all tables and populate it with the
current_timestampevery time a DML statement is executed in the table. For jobs that run multiple times in a day, please maintain a unique audit ID with the status of each run in an audit table.
In the SQL script, if data is appended via
INSERT, add aDELETEstatement on the date of the audit timestamp or the audit ID whose status is “In-Progress” before running theINSERT. This will ensure if anyone is rerunning the entire job after resolving the failure, data duplication won’t happen. Below are sample queries for the same –
DELETE FROM PUBLIC.CPT_LND WHERE AUDIT_ID IN (SELECT AUDIT_ID FROM PRIVATE.CPT_AUDIT WHERE STATUS = 'IN-PROGRESS');
INSERT INTO PUBLIC.CPT_LND
SELECT OBJECT_CONSTRUCT(*) AS RAW_DATA,
CURRENT_TIMESTAMP AS AUDIT_TS,
(SELECT AUDIT_ID FROM PRIVATE.CPT_AUDIT WHERE STATUS = 'IN-PROGRESS') AS AUDIT_ID
FROM PUBLIC.CPT_RAW;
DELETE FROM PUBLIC.CPT_LND WHERE TO_DATE(AUDIT_TS) = CURRENT_DATE;
INSERT INTO PUBLIC.CPT_LND
SELECT OBJECT_CONSTRUCT(*) AS RAW_DATA,
CURRENT_TIMESTAMP AS AUDIT_TS,
NULL AS AUDIT_ID
FROM PUBLIC.CPT_RAW;
Once the failure issue is resolved, use the Run from Component option to re-run the remaining parts of the job rather than running the entire job from the start.

Retry Mechanism
Applications built on cloud infrastructure can be susceptible to intermittent faults such as a temporary loss of network connectivity, temporarily unavailable services, and timeouts that can occur when the service is busy or under heavy load. These types of errors are usually self-correcting and work successfully on retry. An example of using the Retry component to achieve this is shown below –

SDLC Practices
CI/CD and Version Control
Implementing Version Control is imperative for any operational software, and Continuous Integration and Continuous Deployment provide an automated process for doing so.
Although Matillion has features where we can simply export code for our data pipelines from one environment and import it into another, we should not take this approach for deploying and maintaining code as it would lead to a lack of backup and transparency in the longer run.
Thus, we should leverage the connectivity to multiple code repositories and always use any one of them based on what our organization supports. Some of the supported ones for the Matillion ETL/ELT are GitHub, Bitbucket, and Azure DevOps. The recently released Data Productivity Cloud allows users to use their Git repositories.
Managing Environments
Environments are used to establish connectivity to the cloud data warehouse platforms.
We should always maintain separate environments—one for Development, one for Testing, and one for production. Each should be configured strictly to connect to only the respective data warehouse environment. We can have a Production Clone environment if we need to develop or test using production data.
Ideally, these environments should be created on more than 1 million ETL/ELT instances like –
at least 1 non-production instance for Development, Testing
1 production instance to ensure developers do not have write access to the production jobs using proper permission management.
In the Matillion ETL/ELT version, there is a limit on the number of environments available based on the kind of EC2 instance it is running on. So, in a multi-tenant architecture, there is a chance that the total number of environments across all projects might exceed the limit of the instance. In such a scenario, it’s advisable to use a new instance to allow new environments for the remaining tenants if cost permits or reuse an existing one with the necessary access modifications.
However, in the Matillion Data Productivity Cloud, the maximum number of environments per hub instance is 9999, and it can efficiently support a large multi-tenant architecture.
Testing and Validation
We should always test and validate jobs in a lower environment before elevating them to higher environments.
In a Development environment, we can use the Revalidate Job option before running a job to ensure the job is syntactically correct.

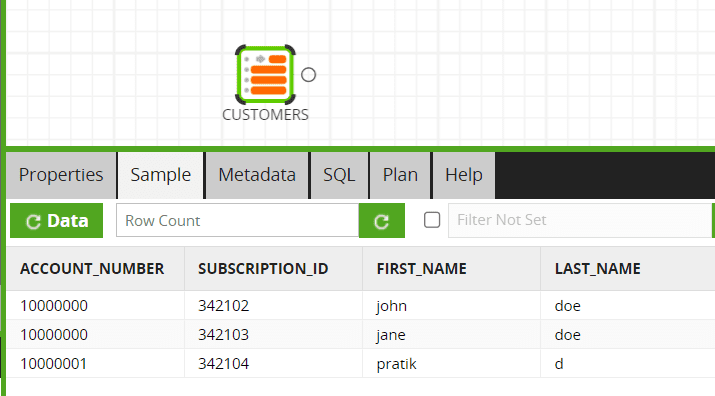
For any components in the transformation jobs, We can validate the sample data by clicking Data in the Sample tab of the component
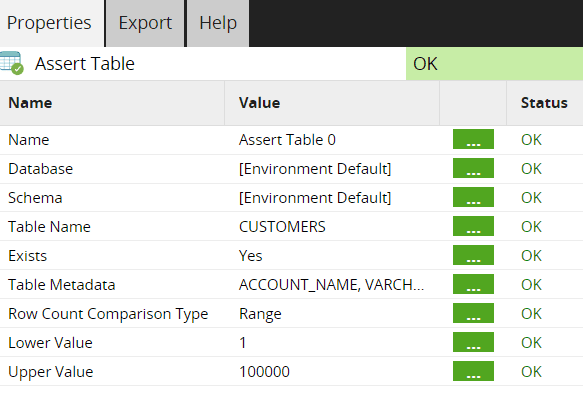
We can additionally add Assert components to ensure the object exists, the DDL of the object is as expected, and for tables, the row count is as expected
In the Testing environment, we should schedule the jobs to run at the required frequency and validate the QA and UAT test cases before promoting them to production.
Security Practices
Credential Management
Credentials like Passwords, API keys, etc., are required by many components in Matillion. We should never maintain them by hard coding them in the code or storing them in the job/environment variables. Rather, we should use the below for Matillion ETL/ELT –
Internal – Matillion comes with its own password manager, which uses different encryption mechanisms based on the cloud platform. We can then use the password name only in the components and even parameterize it.
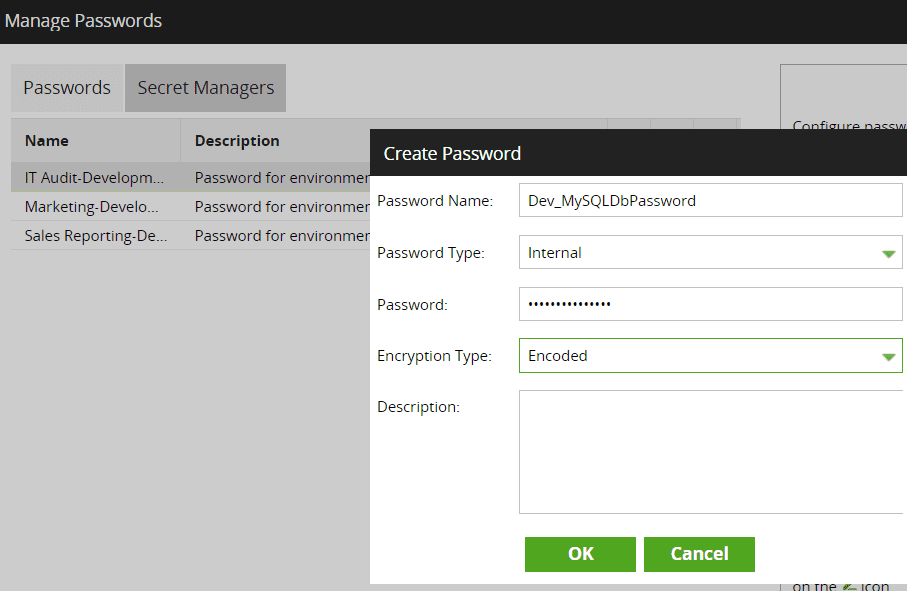
External – It also allows connectivity to third-party secret managers. To do this, we need to integrate third-party secret managers in Matillion ETL.
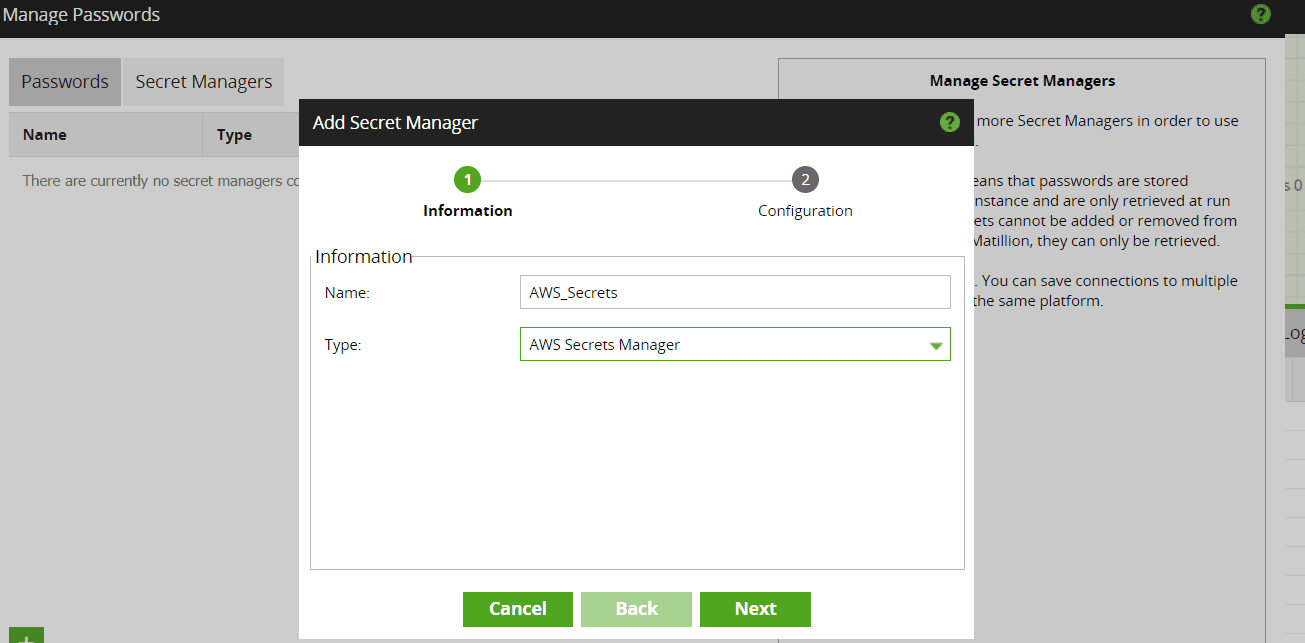
For Matillion Data Productivity Cloud (DPC), there is a section Secrets in the Projects window

We can add secrets containing the credentials, which is equivalent to using the internal password manager. Since it’s already in the Cloud, we can use it to store all the necessary secrets.
Permission Management
Matillion provides built-in groups to which we can add users with predefined permissions. The table below shows an ideal scenario for assigning users to a production instance of Matillion.
| Group Name | Permissions | Instance | Target Users |
|---|---|---|---|
| All Global Access | Grants full access permissions. New users are automatically added to this group and must be reallocated to other groups based on their job roles. | production | Admins |
| Reader | You can view the project and almost all parts of the instance, including API profiles, credentials, OAuths, jobs, and variables. None of these can be edited. | production | All Users |
| Reader with Comments | All “reader” permissions, plus the ability to write notes to annotate jobs | production | Development and Operations Team |
| Runner | All “reader” permissions, plus the ability to run jobs and the individual components within. Schedules cannot be edited or executed. | production | Operations Team |
| Scheduler | All “runner” permissions, plus the ability to edit and execute schedules and related areas such as credentials, drivers, and OAuths. | production | Operations Team |
| Writer | View, edit, and execute all parts of Matillion ETL however, they may keep projects and versions. | production | Admins |
Additionally, the runner and scheduler groups should be modified to remove Execute SQL Script and Execute Python permissions to ensure they cannot run any ad hoc SQL script or Python code from any operational job.
Closing
This blog has discussed multiple sets of best practices for developing jobs in Matillion ETL/ELT. However, worst-case project scenarios might require other workarounds based on a specific requirement. We should always remember that designing an application according to best practices ensures its longevity and scalability, and hence, we should always prioritize following them.
If you have any questions or need further assistance implementing these best practices, don’t hesitate to contact the experts at phData. Our team is here to help you optimize your Matillion jobs and ensure your ETL/ELT processes are as efficient and scalable as possible.
FAQs
Is Matillion an ETL or ELT tool?
Although Matillion is called “Matillion ETL,” it functions more efficiently as an ELT (Extract Load Transform) tool as it can leverage the powerful computing capabilities of the cloud data warehouse platform it is connected to. So, we can use Matillion to extract source data from source applications, load it into the cloud data warehouse, and then transform it as per our needs.
What are Matillion's limitations?
Matillion ETL/ELT’s only limitation is the instance on which it’s hosted. As per the size of the instance, it will support only a defined number of users and environments, as mentioned here. However, this limitation is improved in the fully SaaS Matillion Data Productivity Cloud by increasing the number of environments available.










