

Snowflake Summit 2024 launched numerous features and enhancements targeted at data scientists’ workflows and developer experience. It’s clear that the Snowflake AI Data Cloud is coming of age as a powerful AI/ML platform, and it’s a good time for data scientists to look at adopting Snowflake more heavily to better align with their organization’s data platform and strategy. By adopting more of Snowflake’s functionality for data science, organizations have an opportunity to greatly accelerate AI/ML application development.
In this post, we’ll focus on features that improve data scientists’ day-to-day operations. If you’re interested in the top AI/ML features (models and engineering features), you can check out our dedicated blog post on AI/ML announcements.
Snowflake Notebooks
If you’re a data scientist, you’ve almost certainly used a notebook. You might use one every single day. If you wanted to do that in the past, it might mean launching a notebook in Jupyter, VSCode, or Hex and connecting to Snowflake. Snowflake Notebooks brings that functionality right into the Snowflake UI.
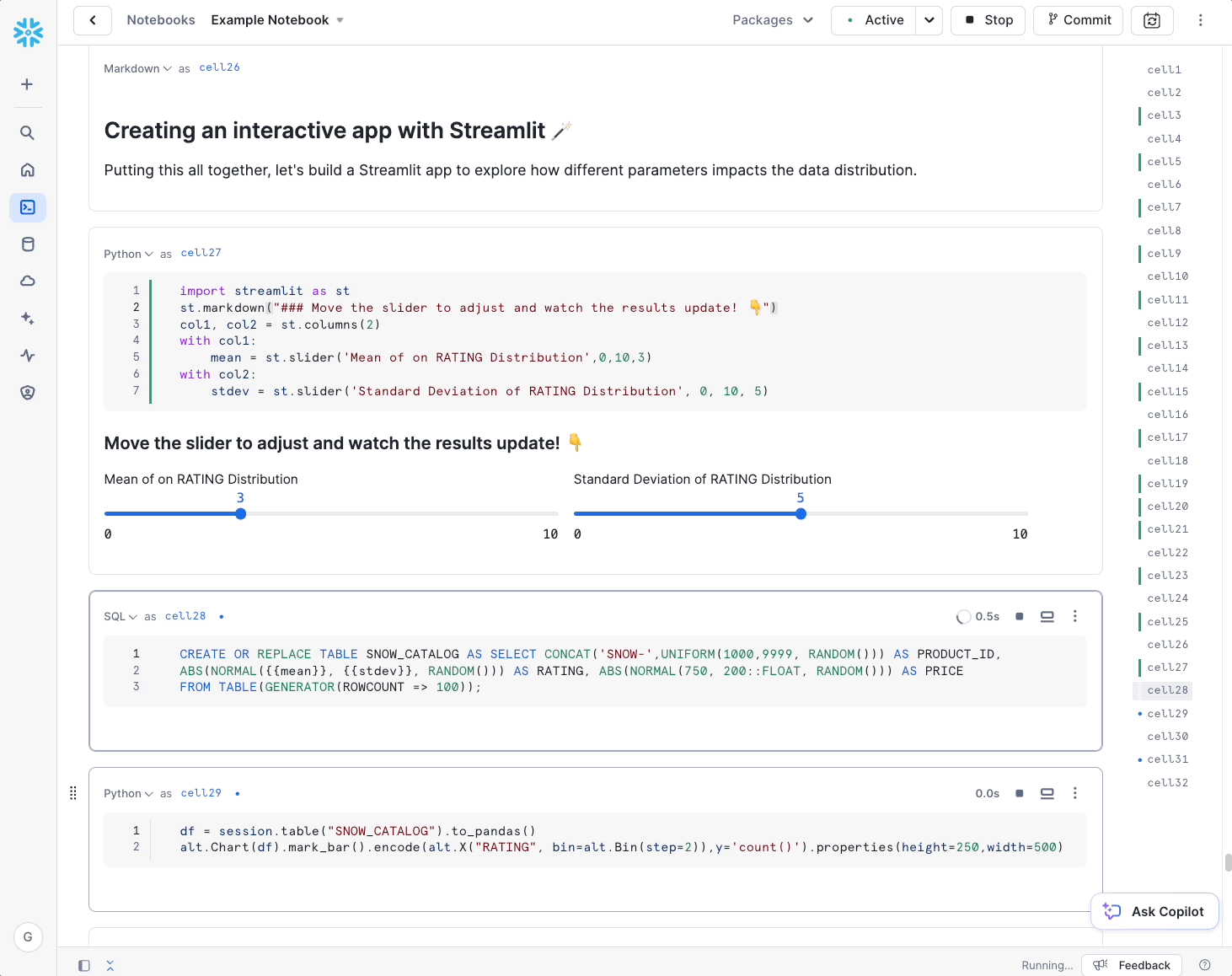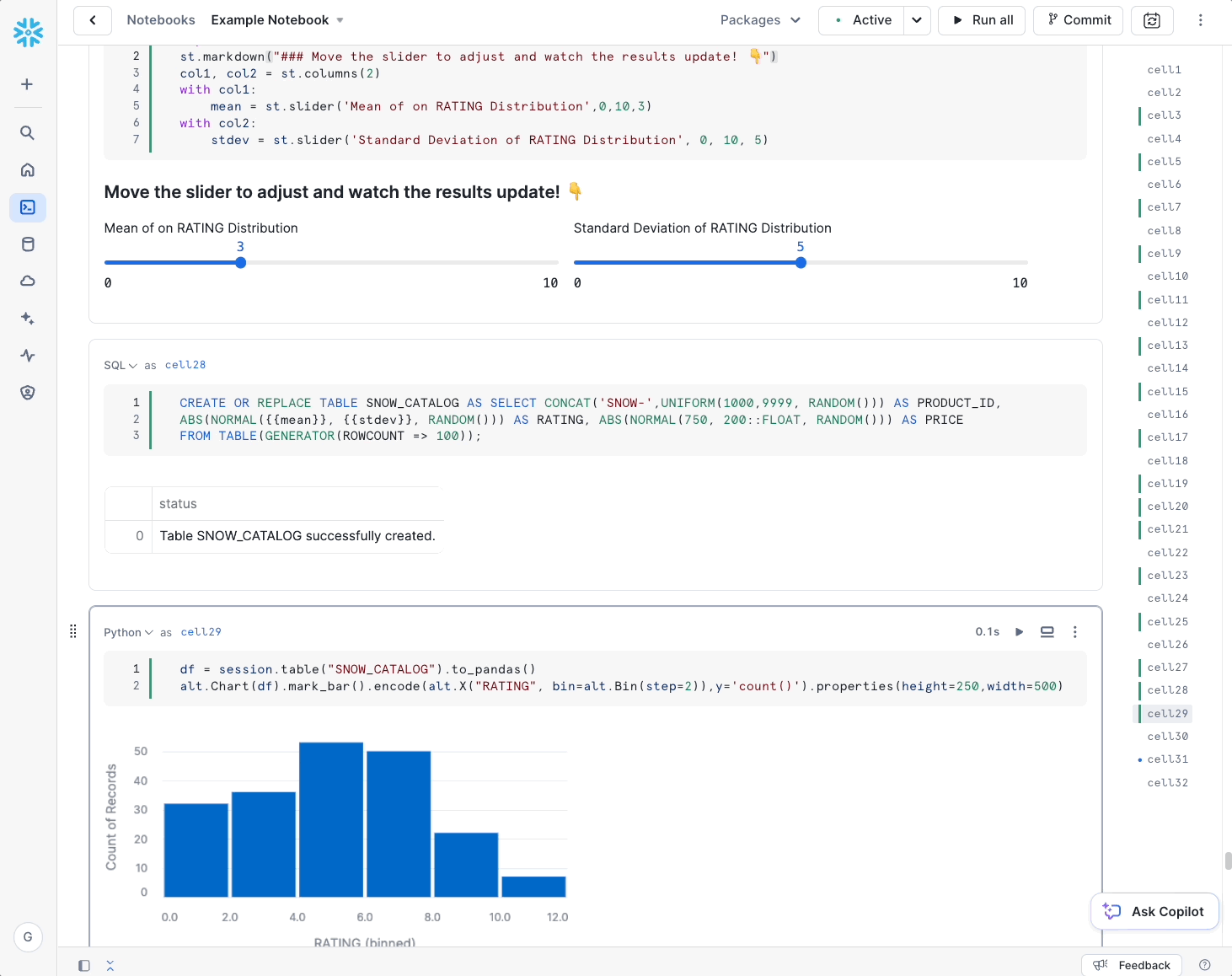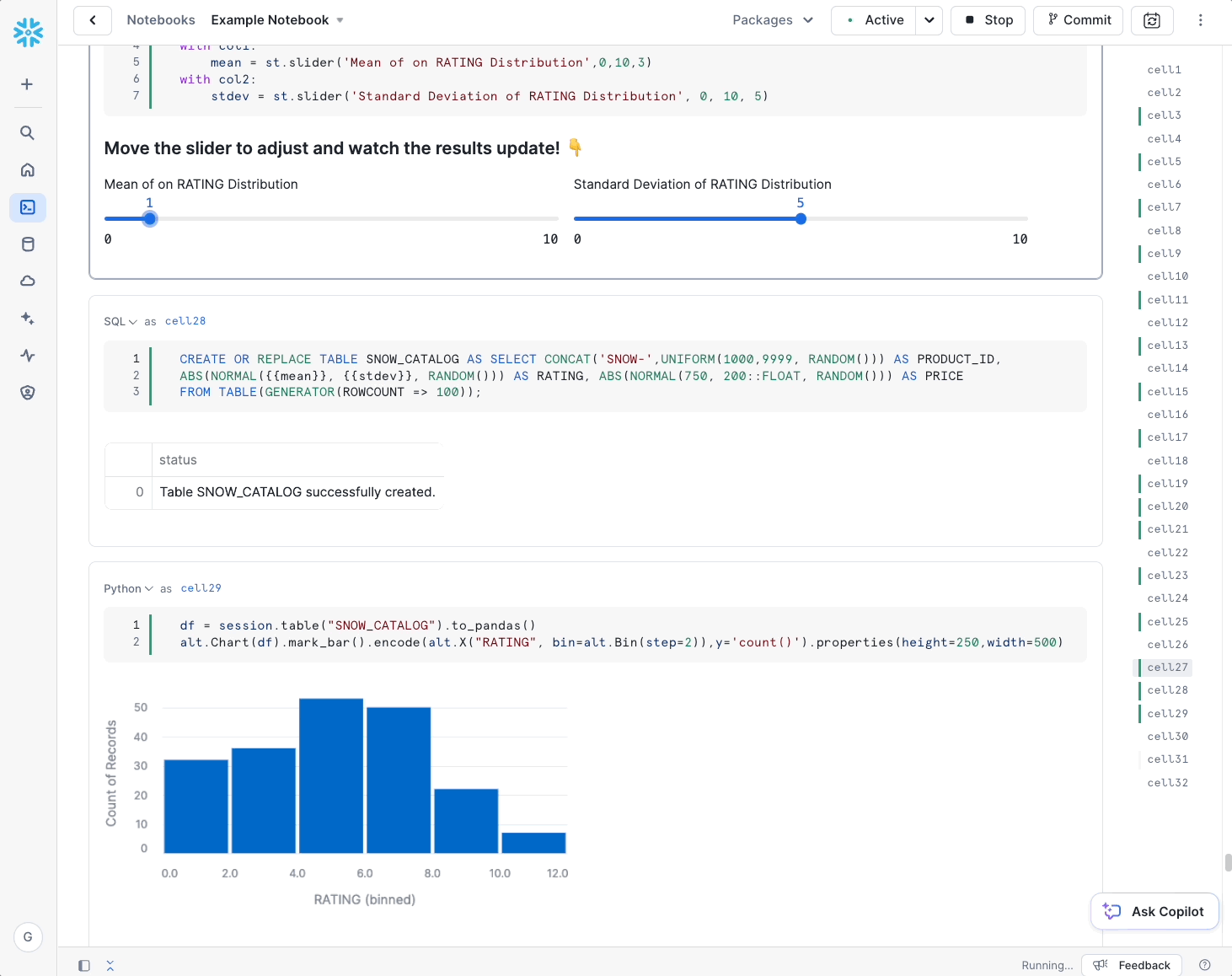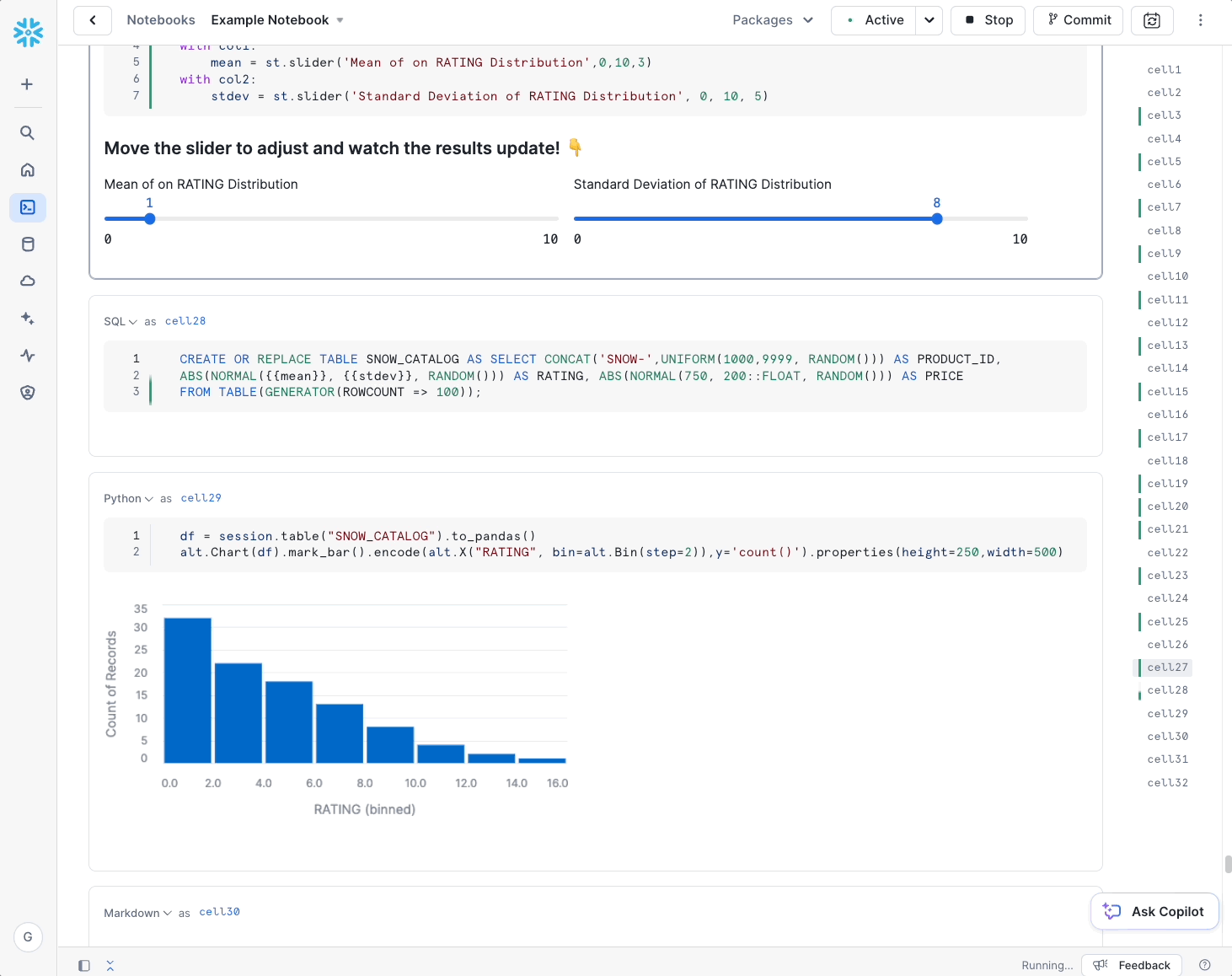
Snowflake’s Notebooks are built on top of Streamlit, so the look and feel are a bit different than Jupyter. That’s not necessarily a bad thing – by building a new notebook from the ground up, Snowflake has been able to natively incorporate features that are not supported natively in Jupyter, such as interactivity (e.g., sliders and inputs) and support for multiple languages (SQL, Python). Aside from those features and a more modern look and feel, working in a Snowflake Notebook should feel pretty natural to users – cell execution and visualization act similarly.
Snowflake’s Notebooks really stand apart in how they authenticate and authorize data access since they natively integrate with Snowflake role-based access control. To access data from a notebook, users simply log into Snowflake, launch their notebook, and select a role to run that notebook. Within the notebook cells, users can immediately run a SQL cell and access data authorized by that role or create a Snowpark session with the same privileges. This makes notebooks great for quick ad-hoc analyses and rapid development.
Once you’re happy with a notebook, you can run it on a schedule or commit it to Git using Snowflake’s new Native Git Integration. While we at phData don’t encourage data science teams to run notebooks in production as a robust MLOps practice, we do see the benefit of data science teams quickly automating repetitive tasks. For library/package customization, Snowflake Notebook kernels can also be extended to custom runtimes using Snowpark Container Services (see below).
Notebooks are now in public preview, so any Snowflake user can find them in the Snowflake UI to get started.
Snowpark Container Services is GA
Snowpark Container Services (SPCS) is now Generally Available on AWS (and soon on Azure). Containers give the ultimate flexibility for application development and environment customization. Most importantly, SPCS gives Snowflake users access to GPU compute resources right inside the Snowflake platform.
Snowflake Notebooks integrate directly with Snowpark Container Services as a runtime, which means that data scientists can customize their Python or GPU environment based on their needs. This means that all the excellent security and governance features of Snowflake now integrate with a universe of customization for data science teams. Working within one platform will help data scientists ship their work to production faster by reducing the amount of refactoring effort necessary for ML engineering teams.
Git Integration
The Snowflake UI now has native Git integration. This means that data science teams can now sync their worksheets and notebooks to Git for collaboration. The Git Integration works by syncing repositories to a Snowflake Stage (object store, akin to Amazon S3 or Azure ADLS). Synced code can then be edited in a Snowflake Worksheet or Notebook.
Power users can also interact with other files in the repository by referencing them based on their stage location – for example, you could create a UDF based on a definition in a .py file. The Git Integration also allows users to switch versions of their code using branches and tags. Snowflake’s Git Integration is now in public preview, so users can start developing today.
Snowflake AI & ML Studio
Snowflake announced its AI & ML Studio, which provides a low-code interface for users to quickly build new applications. This interface includes support for common Predictive AI/ML applications, such as forecasting, anomaly detection, and classification. It also provides entry points for Generative AI, such as Cortex Search for RAG applications or fine-tuning a Cortex LLM.
Many data scientists may dismiss low-code interfaces like Snowflake AI & ML Studio in favor of more advanced techniques that use, for instance, custom Python code and open-source libraries. From our perspective, low-code solutions like this are essential in the AI/ML lifecycle. A low-code solution like AI & ML Studio can be used to demonstrate value quickly before moving on to more advanced techniques. Such tools are also valuable as organizations look to democratize data science and add scale to their AI/ML initiatives.
Snowpark Pandas
Snowpark Pandas provides a new API for Snowpark designed to match the familiar Pandas interface that many data scientists know and love. Snowpark Python is akin to the PySpark Dataframes, which is great for many data engineering and transformation tasks but lacks the more high-level analytical (statistics, feature engineering, etc.) functionality that accelerates the work of data scientists.
The key advantage of Snowpark Pandas is that it uses Snowflake Dataframes/tables behind the scenes rather than the in-memory dataframes of traditional Pandas. This provides data scientists with unprecedented scalability and performance. Rather than worrying about running out of memory, Snowpark Pandas will allow users to simply size up their warehouse when necessary. The same can be done when code is taking too long—Snowpark warehouses can scale up in under a second to provide more compute horsepower and then quickly scale back down to optimize costs.
Posit Partnership and Native App
Snowflake announced a partnership with Posit, which is launching a native application on Snowflake that will provide a workbench for data science teams. Many data science teams use the R language in addition to Python and SQL. Posit’s native application will be ideal for supporting those teams.
Posit is the long-time leader in supporting R users with the R Studio interface. The Posit Native Application will allow users to run R Studio right in Snowflake on top of SPCS while obfuscating more of the technical challenges associated with maintaining application containers.
But Postit’s Native Application capabilities don’t stop at R – it also includes support for hosted VSCode and Jupyter right inside of Snowflake, again on top of SPCS. This makes it much easier for teams with different language preferences to collaborate in harmony. We see terrific value in powering all three of these interfaces with a unified security and governance model within the Snowflake perimeter.
Snowflake Feature Store is GA
We already covered this announcement in our AI/ML announcement blog, so you can head that way for more details. But we’d be remiss not to emphasize the Snowflake Feature Store for the data science crowd.
Feature stores are immensely valuable for driving velocity and collaboration in model development. A feature store helps data science teams reuse features across multiple models by providing a unified interface. But the Snowflake Feature Store stands out in that it also provides transformation capabilities – data scientists can build up transformation pipelines in SQL or Python using Dataframes, and then set a materialization schedule. The new ASOF join makes it easy to do point-in-time joins for feature freshness and correctness (to avoid data leakage).
The Snowflake Feature Store also integrates with Snowflake Horizon to show lineage for feature tables. Under the hood, it uses Dynamic Tables for transformation and materialization or can be pointed to other data for folks developing transformations with tools like dbt. To us, it is impressive and fascinating to see how Snowflake is using its fundamental building blocks (e.g., Horizon and Dynamic Tables) to build up more advanced AI/ML capabilities like the Snowflake Feature Store.
Snowflake Model Registry
The Snowflake Model Registry is also now GA. Model registries are an important part of the ML lifecycle because they effectively decouple the model training process from inference. Data scientists (or automated pipelines) can commit their multiple models to the registry for storage, then inference jobs can consume whichever version of that model is appropriate (imagine A/B testing or dev/QA/staging/production lifecycle) for a given task.
The Snowflake Model Registry is extra special because Models are now native objects in the Snowflake hierarchy. This means that they can be governed using the same RBAC policies as the data used to train the models. This is especially important for sensitive data and modeling applications, such as training customer-specific models. It also means that models can be visualized in Snowflake Horizon for lineage, so a model can descend from the data that was used to train it.
Conclusion
From our perspective, Snowflake Summit 2024 was an exciting week for data scientists. We know that the data science community is particularly opinionated about tooling and that many data scientists are happy in some other environment.
But we also know that some of the largest challenges in data science, AI & ML include privacy, collaboration, and development velocity.
We believe that Snowflake stands apart by providing unified interfaces for collaboration and governance that can address those issues for data science teams. We encourage data scientists to think about how they can do more with the Snowflake AI Data Cloud to help ship applications to their businesses faster.
If you’d like to talk more about how to leverage these features, don’t be afraid to reach out!









